[1] 자바 ORM 표준 JPA 프로그래밍 - 기본편 [1/2]
JPA 사용 이유
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
생산성 JPA에서의 CRUD
저장 : jpa.persist(member)
조회 : Member member = jpa.find(memberId)
수정 : member.setName("변경할 이름")
삭제 : jpa.remove(member)
중요!
단순 조회가 아닌 JPA의 모든 데이터 변경은 트랜잭션 안에서 실행!!
JPQL
- 테이블이 아닌 객체를 대상으로 검색하는 객체 지향 쿼리
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
- JPQL을 한마디로 정의하면 객체 지향 SQL
JPA의 핵심 2가지
1. 객체와 관계형 데이터베이스 매핑하기(Object Relational Mapping)
2. 영속성 컨텍스트
영속성 컨텍스트는
- JPA를 이해하는데 가장 중요한 용어
- 엔티티를 영구 저장하는 환경 이라는 뜻
- 논리적인 개념
- 눈에 보이지 않는다
- 엔티티 매니저를 통해서 영속성 컨텍스트에 접근
- EntityManager.persist(entity)
엔티티의 생명주기
- 비영속 (영속성 컨텍스트와 관계 없는 새로운 상태)
- 영속 (영속성 컨텍스트에 관리되는 상태)
- 준영속 (영속성 컨텍스트에 저장되었다가 분리된 상태)
- 삭제 (삭제된 상태)
사용 코드
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Member findMember = em.find(Member.class, 1L);
//비영속
Member member = new Member();
member.setId(100L);
member.setName("HelloJpa");
//영속
em.persist(member);
tx.commit(); // 커밋을 할때 영속성을 체크해서 쿼리를 날린다.
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
영속 엔티티의 동일성 보장
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.println(a == b); //동일성 비교 true
// 1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션
// 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
변경 감지

위의 매커니즘으로 인해 트랜잭션 commit전에 내부적으로 flush()가 발생해
변경된 값들이 있으면 업데이트를 해준다.
사용 코드
// DB에 있는 기존 데이터 id:150L, name:AAA
Member member = em.find(Member.class, 150L);
member.setName("CCC");
// setName이 변경되어서 commit전에 내부적으로 flush가 동작하여
// 수정된 name만 변경 된다. 결과 데이터 id:150L, name:CCC
tx.commit();
플러시(flush)
영속성 컨텍스트의 변경내용을 데이터베이스에 반영
- 변경 감지(dirty checking)
- 수정된 엔티티 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송(등록,수정,삭제 쿼리)
- 영속성 컨텍스트를 비우지 않음(1차 캐쉬등에 저장되어 있는 것을 지우는게 아님)
- 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화
- 트랜잭션이라는 작업 단위가 중요 -> 커밋 직전에만 동기화 하면 됨
영속성 컨텍스트를 플러시하는 방법
- em.flush() (직접 호출)
- 트랜잭션 커밋 (플러시 자동 호출)
- JPQL 쿼리 실행 (플러시 자동 호출)
기본키 매핑 전략
1. IDENTITY 전략
- 기본 키 생성을 데이터베이스에 위임
- 주로 MySQL, SQL Server, DB2에서 사용
- JPA는 보통 트랜잭셔 커밋 시점에 INSERT SQL을 실행하는데
IDENTITY전략은 INSERT 전까지 키 값을 얻을 수 없다.
때문에 IDENTITY전략을 사용하면 예외로 em.persist()시점에 즉시 INSERT SQL을 실행하고
DB에서 식별자를 조회할 수 있다.
사용 코드
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
} Member member1 = new Member();
member1.setName("A");
member1.setRoleType(RoleType.ADMIN);
//기본은 commit 시점에서 1차 캐쉬에 담긴 insert문을 날리지만,
//IDENTITY전략으로 인해 em.persist(member1);시에 바로 insert문을 날린다.
em.persist(member1);
tx.commit(); 2. SEQUENCE 전략
- 데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한
데이터베이스 오브젝트(ex: 오라클 시퀀스)
- 오라클, DB2, H2에서 사용
사용 코드
@Entity
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}3. TABLE 전략
- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스 흉내
- 장점: 모든 데이터베이스에 적용 가능
- 단점: 성능
사용 코드
@Entity
@TableGenerator(
name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = "MEMBER_SEQ", allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}권장하는 식별자
Long형 + 대체 키 + 키 생성 전략 사용
연관관계 매핑
하나의 Team에 여러 Member이 존재하는 것을 전제로
1. 객체를 테이블에 맞추어 모델링(연관관계가 없는 객체)
- 객체를 테이블에 맞추워 데이터 중심으로 모델링한 경우로 협력 관계가 없다

Member.java
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
// team_id를 외래키로 담는 변수
@Column(name = "TEAM_ID")
private Long teamId;
//getter, setter
}JpaMain.java
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeamId(team.getId());
em.persist(member);
//Team을 조회하기 위해서는 Member을 조회해서 teamId를 찾고
// teamId를 이용해서 Team을 조회해야 한다.(객체 지향적인 방법이 아님)
Member findMember = em.find(Member.class, member.getId());
Long teamId = findMember.getTeamId();
Team findTeam = em.find(Team.class, teamId);
2. 객체 지향 모델링

Member.java
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
// Team객체를 사용한다. (객체 지향적)
// 한Team에 Member이 n만큼 존재하므로 ManyToOne
// 조인 컬럼을 Team테이블의 키 값이랑 연결
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
//getter, setter
}JpaMain.java
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
// member에 team을 직접 넣어준다. 자동으로 키를 찾아 매핑
member.setTeam(team);
em.persist(member);
// 아래의 em.find로 db에서 조회하는 쿼리를 보고싶으면
//em.flush(); //영속성 컨텍스트에 있는 것을 db에 쿼리 날림
//em.clear(); //영속성 컨텍스트 초기화
// Team을 조회할때 findMember에 있는 getTeam으로 바로 조회 가능
// em.find부분이 쿼리로 날라가지 않는다. 이유는 위의 em.persist에서 영속성 컨텍스트
// 1차 캐쉬에 담겨있기 때문에 select문이 날라가지 않음
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();
양방향 연관관계와 연관관계의 주인
양방향 매핑

테이블 연관관계는 외래키로 member, team을 서로 왔다갔다 할 수 있지만,
객체 끼리는 team에 member list를 추가 해줘야한다.
Team.java
@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
// 양방향 매핑위해서 n의 관계에 있는 members 선언
// mappedBy에는 Member에서 joinColumn을 걸어준 필드명을 연결
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
//getter, setter
}Member.java의 team 필드를 Team.java에서 mappedBy에 연결
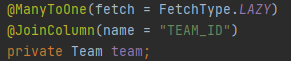
JpaMain.java
Member findMember = em.find(Member.class, member.getId());
// findMember을 통해 getTeam안의 members까지 양방향으로 조회 가능
List<Member> members = findMember.getTeam().getMembers();
for (Member m : members) {
System.out.println("m.getUsername() = " + m.getUsername());
}
연관관계의 주인(Owner) // 양방향인 경우 사용
- 객체의 두 관계중 하나를 연관관계의 주인으로 지정
- 연관관계의 주인만이 외래 키를 관리(등록, 수정)
- 주인이 아닌쪽은 읽기만 가능(mappedBy은 readOnly)
- 주인은 mappedBy 속성 사용X
- 주인이 아니면 mappedBy 속성으로 주인 지정
누구를 주인으로?
- 외래 키가 있는 곳을 주인으로 정해라
- 주인이 아닌 OneToMany에 mappedBy사용
양방향 연관관계 매핑시 주의 예제(Member이 주인, Team에 mappedBy 속성 부여)

아래와 같이 Team.java에는 주인이 아닌 mappedBy가 설정되어 있으므로 조회만 가능하다.
따라서 team.getMembers().add(member);이 들어가지 않는다.

주인(Member)에서만 입력한 방식

위와 같이 했을때 정상적으로 Member, Team에 team_id가 들어가지만 문제점이 있다.
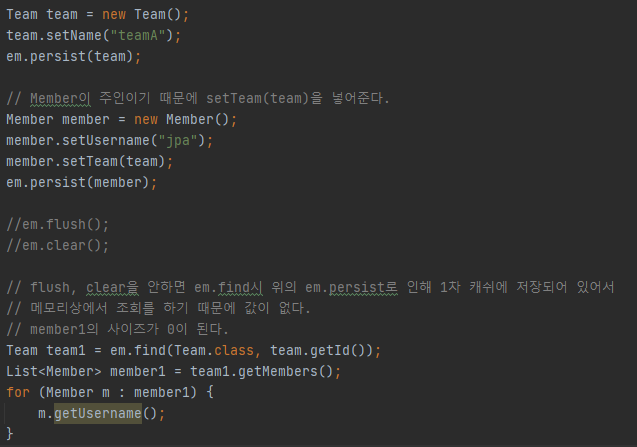
위의 문제로 인해 양방향인 경우 양쪽에 넣어주는 것이 좋다.
이렇게 일일이 양쪽에 넣는 방법을 간편화 한것이 연관관계 편의 메소드이다.

연관관계 편의 메소드 방법
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
/*@Column(name = "TEAM_ID")
private Long teamId;*/
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Team getTeam() {
return team;
}
//public void setTeam(Team team) {
// 웬만하면 set보다는 의미있는 이름으로 편의 메서드명을 지어주는게 좋다
public void changeTeam(Team team) {
this.team = team;
// setter에 연관관계 편의 메서드로 Member.setTeam()을 할때 Team에도 추가를 해준다.
// this는 나 자신 Member의 인스턴스
team.getMembers().add(this);
}
}Team team = new Team();
team.setName("teamA");
em.persist(team);
// Member가 주인이기 때문에 changeTeam(team)을 넣어준다.
Member member = new Member();
member.setUsername("jpa");
member.changeTeam(team);
em.persist(member);
// 연관관계 편의 메소드로 member.changeTeam(team);에서 team에도 같이 들어가기 때문에
// 아래 코드는 없어도 된다.
// team.getMembers().add(member);Memeber.setTeam()할때 team에도 같이 입력되도록 설정
양방향 매핑 정리
- 단방향 매핑만으로도 이미 연관관계 매핑은 완료
- 단방향 매핑으로 설계를 먼저 하고 애플리케이션 구현 할때 필요하면 양방향을 쓰면 된다
- 단방향을 양방향으로 추가할때 테이블에 영향을 주지 않는다
- 객체입장에서 양방향 매핑은 크게 이점이 없다
- 비지니스 로직 기준으로 연관관계 주인을 선택하면 안됨
- 연관관계의 주인은 외래 키의 위치를 기준으로 정해야함(N인 쪽으로)
상속관계 매핑
조인전략(JOINED)
- 각각 테이블로 변환

사용 코드
Movie.java
@Entity
// Item을 상속 받는다
public class Movie extends Item{
private String director;
private String actor;
// getter, setter
}Item.java
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
// @DiscriminatorColumn 어노테이션을 추가해 주면
// ex) Item을 상속받은 Movie에 값이 들어갈시 Item테이블의 DTYPE컬럼에 Moive클래스가 들어간다.
@DiscriminatorColumn
public class Item {
@Id
@GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
private int stockQuantity;
}JpaMain.java
Movie movie = new Movie();
movie.setDirector("A");
movie.setActor("B");
movie.setName("사라지다");
movie.setPrice(10000);
em.persist(movie);결과

단일 테이블 전략(SINGLE_TABLE)
- 통합 테이블로 변환

사용 코드
Item.java
@Entity
// 조인 전략에서 SINGLE_TABLE로 변경
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
// 싱글테이블 전략은 @DiscriminatorColumn을 없애도 기본적으로 DTYPE 컬럼이 추가된다.
//@DiscriminatorColumn
public class Item {
@Id
@GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
private int stockQuantity;
}결과

구현 클래스마다 테이블 전략(TABLE_PER_CLASS)
- 서브타입 테이블로 변환

@MappedSuperclass (공통 매핑 정보)
- 공통 매핑 정보가 필요할 때 사용(ex. id, name 등등)
- 상속매핑이 아니라 공통정보 테이블은 따로 생성이 안된다.

사용 코드
예시) 공통되는 작성자, 작성일, 수정자, 수정일 필드가 필요하다고 했을 경우
BaseEntity.java (공통 필드용 생성)
// 직접적으로 사용할 일은 없기 때문에 abstract(추상 클래스)로 지정한다.
@MappedSuperclass
public abstract class BaseEntity {
private String createdName;
private LocalDateTime createdDate;
//아래와 같이 @Column 이름을 지정할 수 있다.
//@Column(name = "updtName")
private String modifiedName;
private LocalDateTime modifiedDate;
//getter, setter
}Member.java
@Entity
// 공통 클래스를 상속 받는다
public class Member extends BaseEntity{
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
}JpaMain.java
Member member = new Member();
member.setUsername("jpa");
member.setCreatedName("test");
member.setCreatedDate(LocalDateTime.now());
em.persist(member);결과

정리(@MappedSuperclass)
- 상속관계 매핑X (별도의 테이블이 생성되지 않는다)
- 엔티티X, 테이블과 매핑X
- 조회, 검색 불가(em.find(BaseEntity) 불가)
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 참고, @Entity클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속이 가능
프록시와 지연로딩과
실무에선 즉시로딩이 아닌 지연로딩을 사용해야 한다.
@ManyToOne(fetch = FetchType.LAZY)
Member.java
@Entity
public class Member extends BaseEntity{
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
//ManyToOne, OneToOne의 기본은 (fetch = FetchType.EAGER)
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}JpaMain.java
Member member = new Member();
member.setUsername("jpa");
em.persist(member);
em.flush();
em.clear();
// Team과의 연관관계에서 즉시로딩이 되었기 때문에 member을 조회할 때
// select문은 team테이블을 조인해서 전체를 가져온다
Member findMember = em.find(Member.class, member.getId());
지연로딩 적용시
Member.java
@Entity
public class Member extends BaseEntity{
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
// 지연로딩 설정
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
}JpaMain.java
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("jpa");
member.setTeam(team);
em.persist(member);
em.flush(); //영속성 컨텍스트에 담겨있는 것들 실행
em.clear(); //영속성 컨텍스트 초기화
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();
System.out.println("===========================");
// 위에서 영속성컨텍스트를 초기화 해주었고(em.clear), Member 엔티티에 지연로딩을 걸어놔서
// findTeam.getClass()를 하면 프록시 값이 출력이 된다.
System.out.println("team.getClass() = " + findTeam.getClass());
findTeam.getName(); // 직접 team내의 값을 조회할때 select 쿼리가 실행됨.
지연로딩 정리
- 모든 연관관계에 지연 로딩을 사용해라!
- 실무에서 즉시 로딩을 사용하지 마라!
- 필요할 경우 JPQL fetch 조인이나, 엔티티 그래프 기능을 사용할 것
- 즉시 로딩은 상상하지 못한 쿼리가 나간다
영속성 전이(CASCADE)
- 특정 엔티티를 영속 상태로 만들 때, 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때
- 예) 부모 엔티티를 저장할 때 자식 엔티티도 함께 저장
@OneToMany(mappedBy="parent", cascade=CascadeType.PERSIST)
사용 코드


위와 같이 Parent와 Child간에 1대n 양방향 연관관계가 있을때,
Parent에 연관관계 편의 메소드로 Parent 추가시 Child에 값을 넣어주고 싶을 경우
// JpaMain.java
Child child1 = new Child();
Child child2 = new Child();
child1.setName("child1");
child2.setName("child2");
Parent parent = new Parent();
parent.setName("parent!");
parent.addChild(child1);
parent.addChild(child2);
// persist를 insert 만큼 해줘야 한다.
em.persist(child1);
em.persist(child2);
em.persist(parent);위와 같이 3번의 em.persist를 해줘야 한다.
결과

이럴때 CASCADE를 사용하면 특정 엔티티를 persist할때 자동으로 연관된 엔티티도 persist된다.

// JpaMain.java
Child child1 = new Child();
Child child2 = new Child();
child1.setName("child1");
child2.setName("child2");
Parent parent = new Parent();
parent.setName("parent!");
parent.addChild(child1);
parent.addChild(child2);
// Parent엔티티에 cascade가 걸려있으므로 한번만 해주면된다.
em.persist(parent);
임베디드 타입(복합 값 타입)
- 새로운 값 타입을 직접 정의할 수 있음
- JPA는 임베디드 타입(embedded type)이라 함
- 주로 기본 값 타입을 모아서 만들어서 복합 값 타입이라고도 함
- int, String과 같은 값 타입
- @Embeddable : 값 타입을 정의하는 곳에 표시(아래 예제의 Address.java, Period.java)
- @Embedded : 값 타입을 사용하는 곳에 표시(아래 예제의 Member.java)
- 값 타입은 도중에 수정이 불가능한 불변 객체로 설계해야한다.
Member엔티티가 아래와 같을때

아래와 같이 Period, Address라는 객체로 묶어서 사용 할 수 있다.

사용코드
// Address.java
@Embeddable //값 타입을 정의하는 곳에 사용
public class Address {
private String city;
private String street;
private String zipcode;
// 기본 생성자가 있어야 한다.
public Address() {
}
public Address(String city, String street, String zipcode) {
this.city = city;
this.street = street;
this.zipcode = zipcode;
}
// getter, setter
}
====================================================================
// Member.java
@Entity
public class Member{
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
// 시간
@Embedded // 값 타입을 사용하는 곳에 사용
private Period period;
// 주소
@Embedded // 값 타입을 사용하는 곳에 사용
private Address address;
// getter, setter
} JpaMain.java에서 Member 객체 생성 후 주소 값 입력

실행 결과

값 타입의 부작용과 불변 객체
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험하다!
부작용(side effect) 발생
사용 코드
// JpaMain.java
// 임베디드 타입인 주소
Address address = new Address("city","street","1000");
Member member = new Member();
member.setUsername("jpa");
member.setAddress(address);
em.persist(member);
Member member2 = new Member();
member2.setUsername("jpa2");
member2.setAddress(address);
em.persist(member2);위와 같이 실행하면 2번에 insert로 member테이블에 member, member2 인스턴스의 값이 들어간다.
하지만, member의 주소 값만 수정을 하려고 할때 같은 Address 임베디드를 바라보기 때문에 member, member2의 city가 같이 변경되는 문제가 발생한다.
// JpaMain.java
// 임베디드 타입인 주소
Address address = new Address("city","street","1000");
Member member = new Member();
member.setUsername("jpa");
member.setAddress(address);
em.persist(member);
Member member2 = new Member();
member2.setUsername("jpa2");
member2.setAddress(address);
em.persist(member2);
// 이렇게 member 인스턴스에서 주소 임베디드 타입인 city만 변경하려고 하면
// member, member2가 같인 Address 임베디드를 바라보고 있기때문에
// member, member2의 city값이 둘다 바뀌게 된다. (side effect 발생!!)
member.getAddress().setCity("newCity");이를 위한 방법으로는 Address의 인스턴스를 하나 더 만들어도 되지만,
Address라는 임베디드 객체의 setter을 없애고 생성자를 통해서만 생성 가능하도록 불변 객체로 만든다.
불변 객체
- 객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단(setter 제거)
- 값 타입은 불변 객체(immutable object)로 설계해야함
- 불변 객체 : 생성 시점 이후 절대 값을 변경할 수 없는 객체
- 생성자로만 값을 설정하고 수정자(setter)를 만들지 않으면 됨
- 참고: Integer, String은 자바가 제공하는 대표적인 불변 객체
- 불변이라는 작은 제약으로 부작용이라는 큰 재앙을 막을 수 있다.
'Development > JPA' 카테고리의 다른 글
| [6] QueryDSL [1/2] (0) | 2021.07.20 |
|---|---|
| [5] 스프링 데이터 JPA (0) | 2021.07.08 |
| [4] JPA 활용2 강의 내용 [2/2] (0) | 2021.06.17 |
| [2] 자바 ORM 표준 JPA 프로그래밍 - 기본편(객체지향 쿼리) [2/2] (0) | 2021.05.20 |
| [3] JPA 활용1 강의 내용 [1/2] (0) | 2021.04.29 |
